
If you’re here, I’m assuming that you have at least heard of Apache NiFi. If not, that’s okay too. NiFi is a platform built to manage and automate the flow of data between systems. The platform is completely customizable and extremely extensible. This extensibility enables the developer to transform and enrich data in virtually any way imaginable. You can find more information about NiFi here, here, and here.
Out-of-the-Box Error Handling and Retry in NiFi
So, what error handling and retry abilities are supported by NiFi out of the box? Processors within NiFi operate on a file. Once the processing is complete, the processor then either transfers the file to the next processor or terminates. There are several relationships that a processor could use to transfer a file, but the two main relationships are “Success” and “Failure.” So, a file fails because it didn’t meet some criteria or an exception was thrown. This is the first part of handling a failure. Quite recently, NiFi introduced the RetryFlowFile processor. This gives the developer the ability to retry the FlowFile any number of times, while also designating an amount of time to wait between retries. This was a big improvement and really is all that is necessary for any processes that have failed for reasons like network, that may correct themselves before the next retry.
Well, what about processes that will continue to fail without some kind of intervention, be it manual or automated? Do we really want to continue to retry something for n times if the exception thrown wasn’t related to an issue that could potentially correct itself? What happens to the file if it does not succeed before it surpasses the number of retries set by the developer? These are the issues that we want to address. We want to build a reusable flow that can accept data from any processor or process owgroup, smartly route the file to a configurable destination based on the entity and exception, handle ultimate failures in a fashion that will allow re-entry of the FlowFile into the system with all associated attributes, and finally create a means that will then accept those files back into the system.
Building the Example Flow

First, let’s set up our example workflow. In this flow, we are going to use two different process groups. We are using two process groups here to better illustrate how each component on the canvas will be routed to the same reusable framework to handle errors. So, we have two process groups, PG One and PG Two. Let’s examine what each process group is doing.

Process Group One
Process group one starts by generating a FlowFile on a schedule. The FlowFile then triggers an HTTP request to a public API. The API we are using here is https://randomuser.me/api/. This API returns a JSON object that contains an array of JSON with the key “results.”

There are many other properties returned but this highlights the most important property for us, “title.”
Once we receive the response, we then split the JSON. This may result in the FlowFile being split to n number of FlowFiles where n is the number of JSON objects stored in the array. Then we use the EvaluateJsonPath processor to store some JSON key value pairs as attributes. In this processor, we are going to set the filename attribute of the FlowFile to the “Title” property of the JSON. This probably sounds like a bad idea. Well, it is. We are intentionally going to create filename collisions in this example. This will allow us to illustrate how we can programmatically make routing decisions based on the errors returned within NiFi. Then the FlowFile exits PG One and continues to PG Two.

Process Group Two
Process group two simply writes the content of the FlowFile to a given directory and then terminates. The PutFile processor is set up in such a way that if the file already exists, then it will throw an error. Given that we set the filename to the same as Title (a property with a finite number of possibilities), errors will be produced rather quickly. There is an additional step to flatten the JSON, but it is merely here to allow us to illustrate routing of re-entry files.
Basic Retry Reusable Flow
Now it’s time to build the reusable flow. What we will do is create a simple flow and then iterate on it. So, what does the flow need to be reusable?
- Accept inputs from any processor or process group given the appropriate attributes (we are only using process groups)
- Apply logic to the FlowFile based on attributes passed
- WHERE the FlowFile came from
- WHY the FlowFile came to the flow
- HOW MANY times the FlowFile came to the flow
- Route the FlowFile appropriately given the information outlined above

What’s happening here? Upon entering, we have an ExecuteGroovyScript processor that initializes or increments the failure count variable. This processor has a couple of things to take into consideration, though. Given that a FlowFile could fail at one processor, retry successfully, then fail at another processor, this processor that increments the counter cannot simply increment the counter every time. It must ensure that the counter corresponds to the processor in which the FlowFile failed.
Once the counter is incremented, there is a RouteOnAttribute that determines whether or not the FlowFile has exceeded the number of designated retry attempts. If it has, it sends the FlowFile to the right where it will later be logged or send an alert. If it has not, then it continues along the flow to another RouteOnAttribute processor. This processor’s sole responsibility is to route the FlowFile to the appropriate process group output port.

Here on the main canvas, you can see that we've added a route to each process group from the failure. You can also see that there is now a route from each process group to the retry flow. Let’s look at PG One to see what we have added to accept retries as well as sending failures to the retry flow.
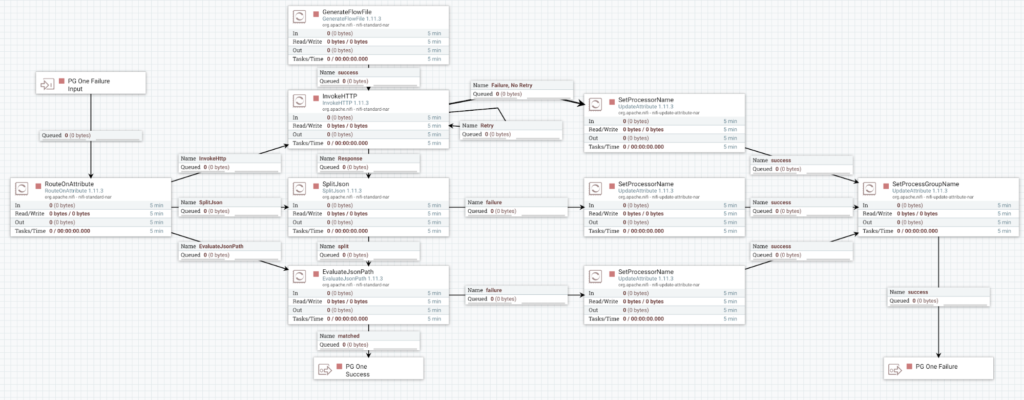
As you can see, there is now an input port as well as a second output port. The input port is accepting files from the retry framework before routing it to the processor where it failed. Additionally, there is now an UpdateAttribute processor to the right of every processor. This is used to update the FlowFile and communicate to the retry flow exactly which processor the FlowFile was at when it failed.
There is also an UpdateAttribute processor shared by every failed route. This is to tell the retry flow which process group the FlowFile failed in. Finally, there is now an output port for failures. This allows the FlowFile to be sent to the retry flow in the event of a failure. I have not identified a better way to do pass the relevant information about where a FlowFile failed in my research. I’ve seen suggestions around using provenance, but this doesn’t seem to be the best solution either. There is most likely a better way to capture the information needed to identify where a failure occurred on a given FlowFile.
This is where we will end this post. So far we’ve created the basic framework that will allow us to retry FlowFiles that fail n number of times. In the next post, we will go over adding the ability to smartly route errors based on the processor, logging errors, a framework for programmatic “fixes,” and enabling the re-entry of a FlowFile after it has been manually adjusted to address an issue.


